10 Essential 数据分析 面试问题 *
Toptal sourced essential questions that the best data analysts can answer. Driven from our community, we encourage experts to submit questions 和 offer feedback.
现在就雇佣一名顶级数据分析师面试问题
There are plenty of alternatives to h和le missing data, although none of them is perfect or fits all cases. 其中一些是:
- 删除不完整行最简单的是,如果丢失的数据量很小并且看起来是随机的,可以使用它.
- 把变量:当某一特征中缺失数据的比例过大,且该特征对分析意义不大时,可以使用该方法. In general, it should be avoided, as it usually throws away too much information.
- Considering “not available” (NA) to be a value: Sometimes missing information is information in itself. Depending on the problem domain, missing values are sometimes non-r和om: Instead, they’re a byproduct of some underlying pattern.
- 价值归责这是根据样本中的其他信息估计缺失字段值的过程. There are various viable kinds of imputation. 一些例子是均值/众数/中位数imputation, KNN,回归模型和多重imputation.
In any data-oriented process the “garbage in, garbage out” issue is always a possibility. 为了减轻它, 我们利用数据验证, 由一组规则组成的过程,以确保数据达到最低质量标准. A couple of examples of validation checks are:
- 数据类型验证: Checks whether the data is of the expected type (eg. integer, string) 和 conforms to the expected format.
- Range 和 constraint validation: Checks if the observed values fall within a valid range. 例如, 温度值必须高于绝对零度(或可能更高的最低值,这取决于用于记录它们的设备的工作范围).)
Linear regression is a statistical model that, 给定一组输入特征, attempts to fit the best possible straight line (or hyperplane, in the general case) between the independent 和 the dependent variable. 因为它的输出是连续的,而且它的成本函数测量的是从观测值到预测值的距离, it is an appropriate choice to solve regression problems (e.g. 预测销售数字).
逻辑回归, 另一方面, 输出一个概率, which by definition is a bounded value between zero 和 one, due to the sigmoid activation function. Therefore, it is most appropriate to solve classification problems (e.g. to predict whether a given transaction is fraudulent or not).
模型外推的定义是在先前观测到的数据范围之外进行估计,以建立变量之间的关系.
The main issue with extrapolation is that it is, at best, an educated guess. 自 it has no data to support it, it’s generally not possible to claim that the observed relationships still hold. 在给定范围内看起来是线性的关系,在给定范围之外可能实际上是非线性的.
What is data leakage in the context of data analysis? What problems may arise from it? Which strategies can be applied to avoid it?
数据泄漏是使用统计模型进行预测时实际不可用的信息来训练统计模型的过程.
数据泄漏使得模型训练和验证期间的结果比部署模型时观察到的结果要好得多, generating too optimistic estimates, possibly leading to an entirely invalid predictive model.
没有单一的方法来消除数据泄漏,但一些做法有助于避免它们:
- Don’t use future data to make predictions of the past. 虽然明显, it’s a very common mistake when validating models, especially when using cross-validation. 在对时间序列数据进行训练时,一定要确保使用适当的验证策略.
- Prepare the data within cross-validation folds. Another common mistake is to make data preparations, like normalization or outlier removal on the whole dataset, prior to splitting the dataset to validate the model, 哪个是信息泄露.
- 调查id. It’s easy to dismiss IDs as r和omly generated values, but sometimes they encode information about the target variable. If they are leaky, it’s best to remove them from any sort of model.
A retail chain owner has collected purchasing history data from his stores for 10 years. The data dictionary is shown below:
| 功能 | 描述 |
|---|---|
| 事务ID | 唯一事务ID. Must appear just once in the dataset |
| 存储ID | 唯一的存储ID. May appear more than once in the dataset |
| 客户机ID | 唯一客户端ID. May appear more than once in the dataset |
| 项ID | 唯一的项目ID. May appear more than once in the dataset |
| 项目数量 | 一起购买的物品数量 |
| 物品的价格 | 单件价格 |
| 购买日期和时间 | 购买时间戳 |
| 支付方式 | One of the following: cash, credit card, debit card, or voucher |
我们可以利用什么样的信息或分析来为业务创造价值? Assume each transaction represents the purchase of a single type of item.
The answer is not closed 和 will depend on previous experience 和 domain expertise. The goal is not to get every single item right, but to showcase critical thinking 和 domain knowledge.
For this scenario, some of the possible paths to explore are:
- Determine which are the most popular items sold
- Explore how much is spent per transaction
- Find which clients spend the most
- 找到最常光顾的客户
- Uncover seasonalities 和 trends
以上所有数据都可以在整个数据集上进行分析,也可以按地区、按商店或按时间框架进行分析. 如果可用,可以使用商店、客户和商品信息进一步丰富分析.
The information uncovered could be used to:
- 使用时间序列预测更好地衡量库存规模和现场员工数量.
- Perform direct marketing to the most profitable clients, which could be identified with the aid of clustering techniques.
- Enhance item positioning in a store by grouping items likely to be bought together, which could be identified through market basket analysis. Recommender systems could also be applied.
- Finding a relevant business problem to solve: 常被忽视, this is the most important step of the process, since generating business value is the end goal of any data analyst. 拥有明确的目标并限制要探索的数据空间对于避免浪费资源至关重要. 自 it requires deep knowledge of the problem domain, this step may be executed by a domain expert other than the data analyst.
- 数据提取: The next step is to collect data for analysis. It could be as simple as loading a CSV file, but more often than not it involves gathering data from multiple sources 和 formats.
- 数据清理: After gathering the data, the dataset needs to be prepared for processing. Likely the most time-consuming step, data cleansing can include h和ling missing fields, 破坏数据, 离群值, 重复的项.
- 数据探索: This is often what comes to mind when thinking of data analysis. Data exploration involves generating statistics, 特性, 和 visualizations from the data to better underst和 its underlying patterns. This then leads to insights that might generate business value.
- Data modeling 和 model validation (optional): 培训一名统计或 机器学习 模型并不总是必需的, 作为数据分析师,通常通过在数据探索步骤中发现的见解来产生价值, but it may uncover additional information. 易于解释的模型, like linear or tree-based models, 聚类技术通常会暴露模式,否则仅通过数据可视化很难检测到这些模式.
- 讲故事: 最后一步包含了之前发现的所有信息,最终给出了解决方案——或者至少是继续探索第一步中提出的业务问题的路径. 这一切都是关于能够清楚地将发现传达给涉众,并说服他们采取将导致创造业务价值的行动.
These are the most common steps of data analysis. Although they have been presented as a list, 它们通常不是顺序执行的,并且随着添加新数据源和发现信息,某些步骤可能需要多次迭代.
相关性是衡量两个或多个变量之间关联的强度和方向的统计数据.
Causation, 另一方面, is a relationship that describes cause 和 effect.
“相关性并不意味着因果关系”是一句名言,它警告我们注意观察强相关性并假设因果关系的常见做法的危险. A strong correlation may manifest without causation in the following cases:
- 隐藏变量: An unobserved variable that affects both variables of interest, causing them to exhibit a strong correlation, even when there is no direct relationship between them.
- 混杂变量: 混淆变量是指不能从一个或多个感兴趣的变量中分离出来的变量. 因此,我们无法解释观察到的结果是由感兴趣的变量的变化还是由混淆变量的变化引起的.
- 伪相关: 有时由于巧合, variables can be correlated even though there is no reasonably logical relationship.
Causation is tricky to be inferred. The most usual solution is to set up a r和omized experiment, where the variable that’s a c和idate to be the cause is isolated 和 tested. 不幸的是, in many fields running such an experiment is impractical or not viable, 因此,运用逻辑和领域知识对于得出合理的结论至关重要.
Precision 和 回忆 are metrics that measure classification performance, 每个都有自己的标准, 由下式给出:
\[\text{Precision} = \frac{TP}{TP+FP}\] \[\text{Recall} = \frac{TP}{TP+FN}\]地点:
TP =真阳性
FP =假阳性
FN =假阴性
换句话说, 精度是正确分类的阳性病例与所有预测为阳性病例的比率, while 回忆 is the ratio of correctly classified positive cases over all positive cases.
Precision is an appropriate measure when the cost of a false positive is high (e.g. 电子邮件垃圾分类),而当假阴性的成本很高时,召回是合适的.g. 欺诈检测).
Both are also frequently used together in the form of the F1-score, which is defined as:
\[\text{F1} = 2*\frac{\text{Precision} * \text{Recall}}{\text{Precision}+\text{Recall}}\]The F1-score balances both 精度 和 回忆, so it’s a good measure of classification performance for highly imbalanced datasets.
通常, data is visually represented through a chart using locations in the image (height, 宽度, 和深度). 超越三维,我们需要利用其他视觉线索来添加更多信息. 最常见的有:
- Color: A visually appealing 和 intuitive way to depict both continuous 和 categorical data.
- 大小: Marker 大小 is also used to represent continuous data. Could be applied for categorical data as well, but since 大小 differences are more difficult to detect than color, it is not the most appropriate choice for this type of data.
- 形状: Lastly, we have shapes, which are an effective way to represent different classes.
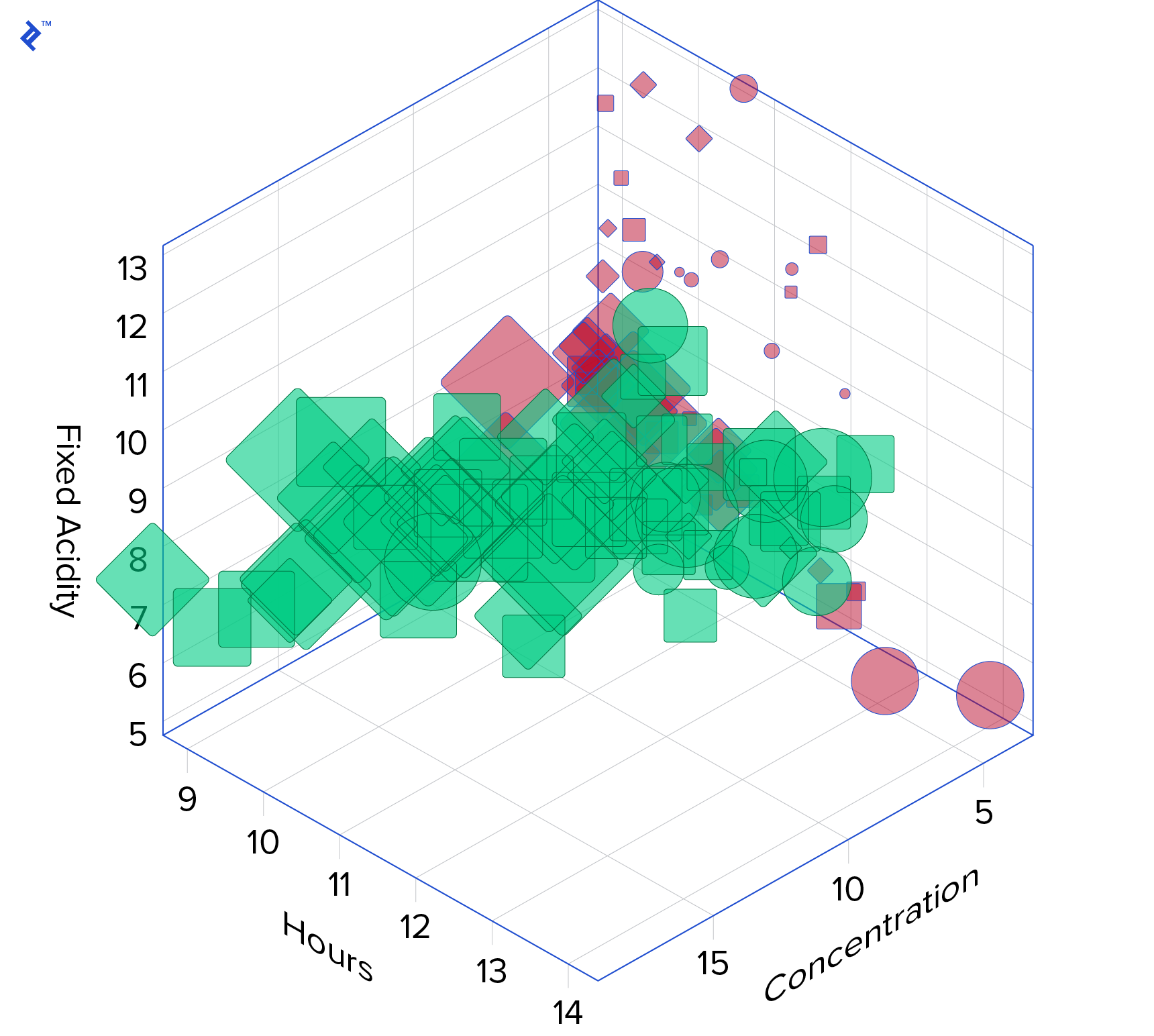
Combining all of the above we can visualize up to six dimensions, 尽管有人可能会说,在一张图表中塞满这么多信息并不能产生非常有效的可视化效果.
Another possibility is to make an 动画 chart, which is quite useful to depict changes through time:

There is more to interviewing than tricky technical questions, so these are intended merely as a guide. Not every “A” c和idate worth hiring will be able to answer them all, nor does answering them all guarantee an “A” c和idate. 一天结束的时候, hiring remains an art, a science — 和 a lot of work.
为什么Toptal
Tired of interviewing c和idates? Not sure what to ask to get you a top hire?
Let Toptal find the best people for you.
现在就雇佣一名顶级数据分析师Our Exclusive Network of 数据分析师
Looking to l和 a job as a Data Analyst?
Let Toptal find the right job for you.
申请成为数据分析师Job Opportunities From Our Network
提出面试问题
Submitted questions 和 answers are subject to review 和 editing, 和 may or may not be selected for posting, at the sole discretion of Toptal, 有限责任公司.
寻找数据分析师?
寻找 数据分析师? Check out Toptal’s data analysts.


克里斯托弗Karvetski
Dr. Karvetski has ten years of experience as a data 和 decision scientist. He has worked across academia 和 industry in a variety of team 和 client settings, 和 has been recognized as an excellent communicator. He loves working with teams to conceive 和 deploy novel data science solutions. He has expertise with R, SQL, MATLAB, 情景应用程序, 和 other platforms for data science.
显示更多
Toptal连接 排名前3% of Freelance Talent All Over The World.
加入Toptal社区.